0️⃣ 3줄 요약
- OS는 “있으면 좋은 것”이 아니라, 장애를 막는 안전장치다.
- 커널은 프로그램 대신 CPU·메모리·디스크·네트워크를 중재한다.
- RAM 용량보다 swap·OOM·I/O wait을 볼 줄 아는 게 더 중요하다.
1️⃣ OS가 왜 필요하냐고요? “장애가 나면” 바로 답이 나옵니다
운영체제는 평소엔 존재감이 거의 없습니다.
그런데 서버가 느려지거나, 서비스가 갑자기 죽으면 상황이 달라집니다.
제가 실제로 겪었던 케이스들입니다.
- 사이트가 갑자기 느려짐 → CPU 100% / I/O wait 증가 / swap 사용
- 잘 돌아가던 서비스가 새벽에 죽음 → OOM Killer
- 디스크 꽉 참 → 로그·백업·Docker 잔여물 폭증
- SSH는 되는데 서비스는 안 뜸 → 권한/실행 계정 문제
이때 OS는 배경이 아니라 사건 현장입니다.
커널·프로세스·메모리를 모르면 원인 추적 속도가 확실히 느립니다.
2️⃣ 한 문장 정의
운영체제(OS)는 프로그램이 하드웨어를 안전하게 쓰도록 중재하는 관리자입니다.
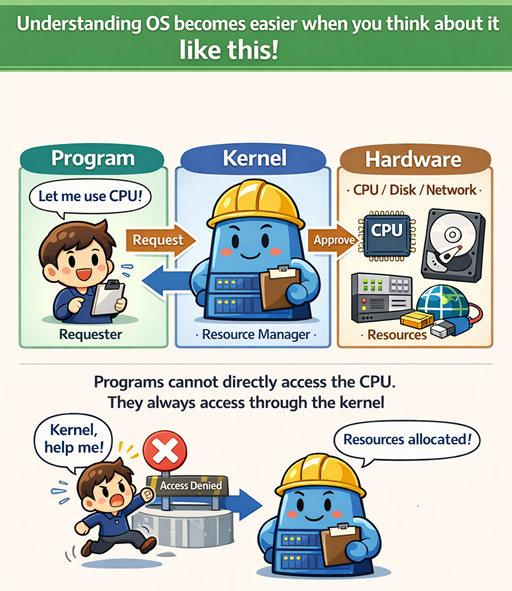
3️⃣ 그림 하나로 이해하기
OS를 이렇게 생각하면 편합니다.
- 프로그램 = 요청하는 사람
- 하드웨어(CPU/디스크/네트워크) = 자원
- 커널 = 자원 배분 관리자
프로그램은 직접 CPU를 잡지 못합니다.
항상 커널을 통해서만 접근합니다.
4️⃣ 커널(Kernel): 내가 모르는 사이에 다 대신 처리하는 관리자
워드프레스 기준으로 보면 흐름은 이렇습니다.
- 브라우저 요청 도착
- 커널이 네트워크 패킷 수신
- 웹서버(Nginx/Apache) 프로세스에 전달
- 디스크에서 파일 읽기
- PHP 프로세스가 DB 접근
- 결과를 다시 네트워크로 전송
여기서 느려지면 보통 커널이 관리하는 자원 중 하나가 병목입니다.
제가 실제로 겪은 사례 3가지
✔ CPU는 30%인데 서버가 멈춘 느낌
→ 원인은 I/O wait (디스크 대기)
✔ 트래픽 증가 후 502/504
→ 동시 연결 수 / 파일 핸들 한계
✔ systemd로 실행하면 실패
→ 실행 계정 권한 문제
앱만 보면 안 보이고, OS 자원 관점으로 봐야 잡히는 문제입니다.
5️⃣ 프로세스(Process): 범인을 찾는 출발점
실무에서 OS를 보는 가장 현실적인 이유는 단순합니다.
누가 자원을 먹고 있는지 찾는 것
제가 항상 하는 순서:
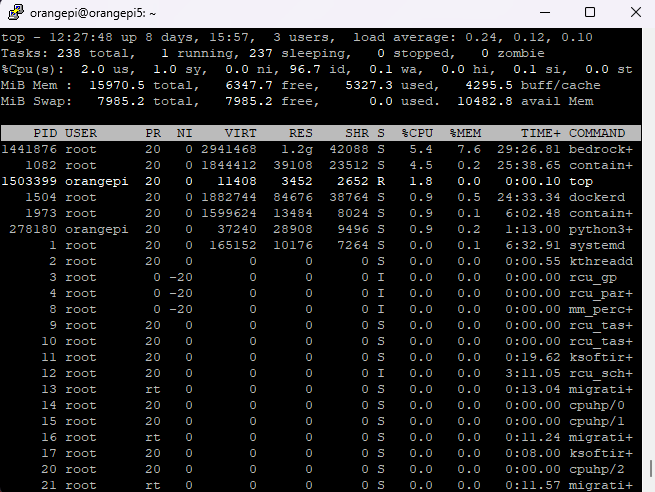
top
free -h
df -h
- CPU 100% 프로세스 → 무한 루프/계산 문제 가능성
- 메모리 계속 증가 → 누수 가능성
- 프로세스 사라짐 → OOM / 크래시 확인
그리고 경험상, 프로세스는 거짓말을 하지 않습니다.
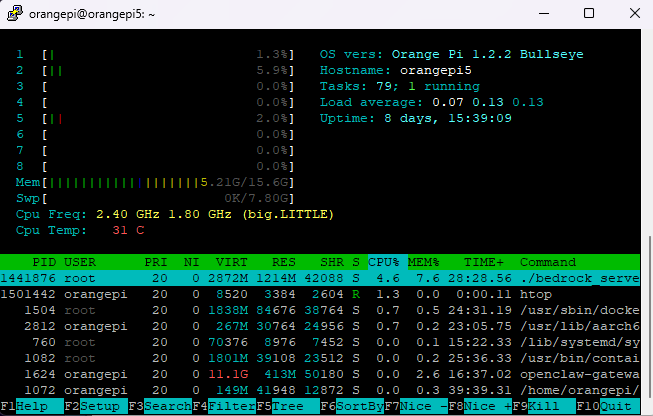
- CPU 100% 찍는 프로세스가 있으면, 뭔가 계산/루프/대기 문제가 있고
- 메모리가 계속 늘면, 누수(Leak)거나 캐시가 풀리지 않는 구조일 가능성이 높고
- 프로세스가 죽어 있으면, 누가 죽였는지(OOM/크래시/kill)를 OS 로그에서 찾을 수 있어요.
“프로세스가 여러 개라서 더 안전해진” 경험
예전에 한 번은 웹서버+PHP가 한 덩어리처럼 꽉 묶여 있어서
하나가 죽으면 전체가 불안정해졌던 적이 있어요.
그 뒤로는 프로세스 분리/풀 관리가 되는 구조(Nginx ↔ PHP-FPM)를 선호하게 됐습니다.
- 문제가 생겨도 “부분”만 영향을 받는 구조
- 그리고 문제를 “프로세스 단위”로 좁혀서 해결이 쉬움
6️⃣ 메모리(Memory): RAM보다 swap과 OOM이 핵심
초보 때는 “RAM이 많으면 안전하다”고 생각했습니다.
운영해보니 포인트는 다르더군요.
메모리 문제의 전형적인 흐름
- 체감상 느려짐
- swap 사용량 증가
- load 상승
- OOM Killer가 프로세스 강제 종료
가장 당황스러운 순간은:
“내가 내린 적 없는데 서비스가 죽어 있음”
하지만 OS는 흔적을 남깁니다.
dmesg | grep -i oom
journalctl -xe
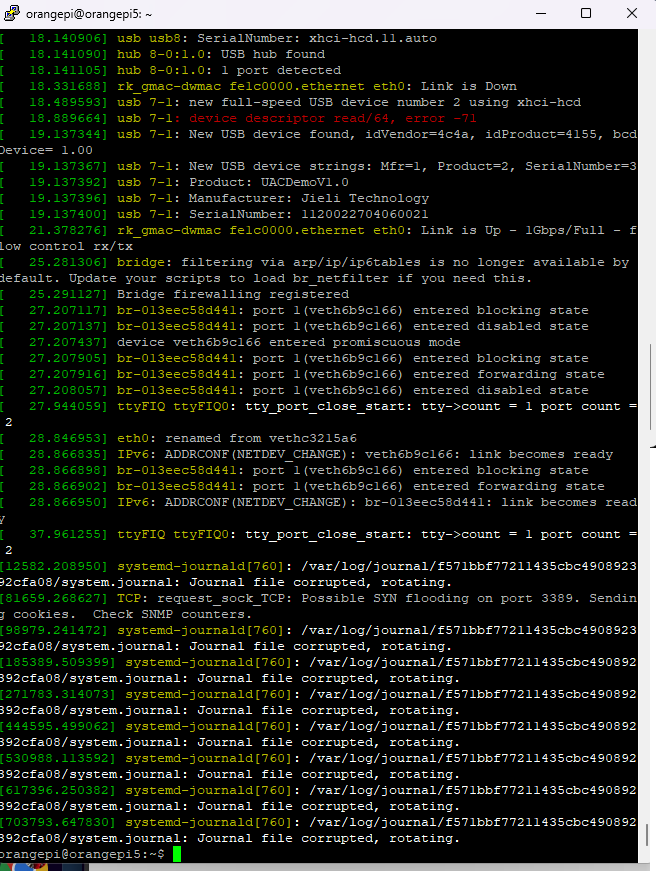
여기서 거의 다 나옵니다.
오해했던 부분: RAM 사용률
free -h에서 RAM이 거의 다 차 있어도
그게 반드시 문제는 아닙니다.
리눅스는 캐시를 적극 활용합니다.
진짜 위험 신호는:
- swap이 계속 증가
- OOM 로그 발생
- 리눅스면 보통 dmesg / journalctl에서 OOM 흔적을 찾을 수 있어요.
캐시는 “정상”인데, 오해하기 쉬웠던 경험
리눅스에서 free -h 보면 RAM이 대부분 사용 중으로 보이는데
그게 꼭 문제는 아니더라고요.
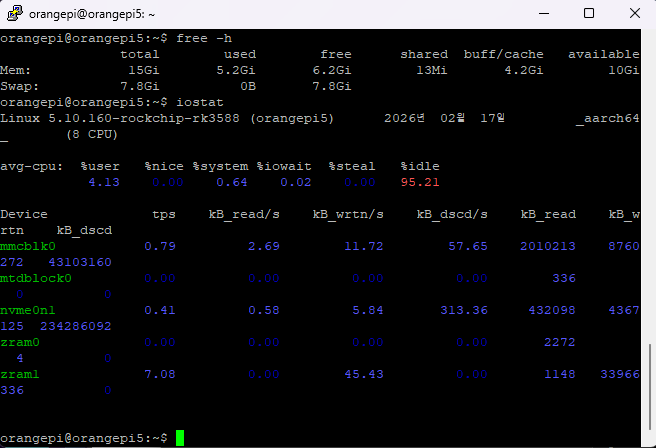
- OS가 캐시로 RAM을 적극 활용하는 게 정상
- 문제는 캐시가 아니라 스왑이 늘고 반응이 무너질 때입니다.
즉, “RAM 사용률”보다 “swap/oom”을 더 경계하게 됐어요.
7️⃣ 워드프레스 글 하나 열 때 OS 안에서 벌어지는 일
사용자 요청
→ 커널이 네트워크 처리
→ 웹서버 프로세스 실행
→ PHP-FPM 동작
→ DB 접근 (네트워크/디스크 I/O)
→ 응답 반환
이 중 하나라도 병목이면 체감이 바로 느려집니다.
그래서 OS를 이해하면 이런 감이 생깁니다.
“이건 코드가 아니라 I/O 같다.”
“CPU가 아니라 메모리 압박이다.”
이 감이 운영에선 정말 큽니다.
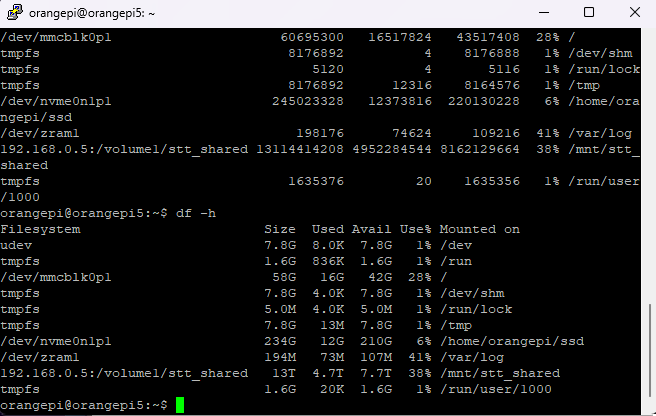
8️⃣ 제가 쓰는 3분 점검 루틴
서버가 느릴 때 저는 거의 이 순서입니다.
top
free -h
df -h
iostat
journalctl -xe
- 누가 CPU/RAM 먹는지
- swap 증가 여부
- 디스크 용량
- I/O wait
- OOM/크래시 로그
이 루틴이 습관이 되면
OS는 시험 과목이 아니라 장애 해결 지도가 됩니다.
9️⃣ 자주 하는 실수 TOP3
1️⃣ CPU만 보고 판단
→ 실제 원인은 I/O wait
2️⃣ RAM 사용률만 보고 “메모리 부족” 단정
→ 캐시 정상 사용일 수 있음
3️⃣ 애플리케이션 로그만 보고 OS 로그 안 봄
→ OOM은 커널 로그에 남음
🔟 체크리스트
- CPU %만 보지 않는다
- swap 증가 여부 확인
- OOM 로그 확인
- 디스크 용량 주기 점검
- 프로세스 단위로 문제를 좁힌다
FAQ
Q1. OS를 알면 코딩에도 도움이 되나요?
네. 왜 느려지는지, 왜 죽는지가 보이기 시작합니다.
Q2. 커널을 직접 건드릴 일도 있나요?
직접 수정은 거의 없지만, 로그와 자원 상태를 읽는 일은 매우 많습니다.
Q3. 메모리 위험 신호는 무엇인가요?
RAM 사용률보다 swap 증가와 OOM 로그가 더 위험 신호였습니다.